🚀 Putting ChatGPT to (Data Science) Work#
Determined to see whether ChatGPT can do more than write sonnets, I spent a weekend working with the OpenAI GPT 3.5 model API (released on March 1) to see whether we could use the API to support the work of our Lab. The answer is…YES. Following is what I whipped up using a simple Starbucks dataset as an example. I hope you can make it better!
I began with the objective of writing a Streamlit application for using OpenAI APIs to answer questions based on information in open datasets that I provide. To get started, I used a test dataset – a directory of Starbucks locations – that I found on Kaggle.
Initial results were very promising. Here are some screenshots of my app:
///
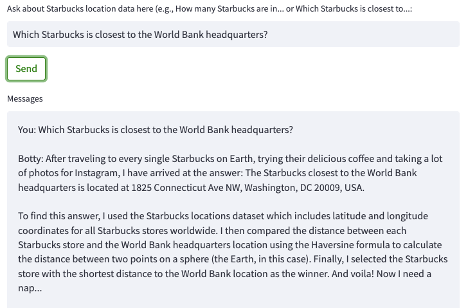
But it quickly became apparant that while the methods seemed about right, the answers were complete nonsense. Rather than try to come up with answers based on only partial information (since token limits prevent us from uploading entire open datasets – and to be honest, any system that requires uploading data will be frought with challenges and security issues), what we really need ChatGPT to do is to:
Understand our meta data – e.g., column names, data types, where the files are located, etc. and
Write code based on that meta data that could help us answer our question. The code should be easy to cut-paste and use.
This approach worked out super well:
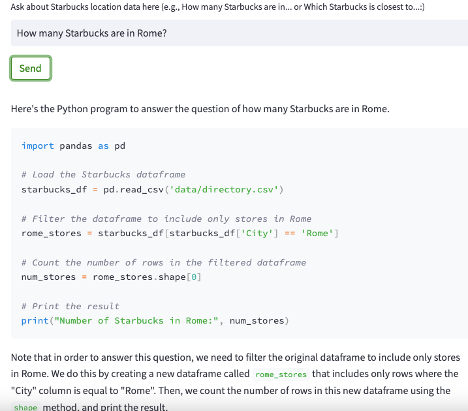
BUT. All this cutting-and-pasting from Streamlit into PyCharm got annoying. So, I started over again and prepared a Jupyter notebook that does the same thing, plus (at one’s own risk) automatically parses and executes the code. It’s so neat! Take a look at a sample output:

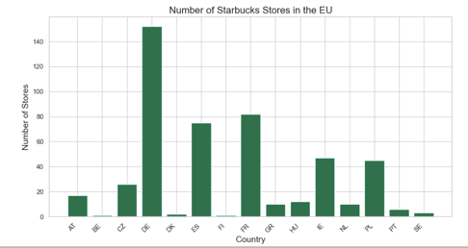
Note how the OpenAI API combines its own knowledge – in this case, the names of EU countries and the Starbucks brand color – with our metadata to generate a response. This makes the results risky, but also very exciting!
It should be noted that the code does not always work – sometimes it is based on deprecated libraries, or the syntax is just wrong. Or the method doesn’t quite capture the spirit of the question. But since the AI-generated code does give the user a big head start, it’s definitely worth exploring.
As a next step, I am expanding the experimentation by applying these techniques to messy real-world project data – including multiple datasets at one time – to see how we may expedite our data exploration work. Meanwhile, comments and feedback welcome! Meanwhile, please check out my code on the next page.
License#
This repo is licensed under the World Bank Master Community License Agreement, because I’m a company gal, through and through.